March 26, 2021Is Marketing about to wake up from its Adtech nightmare?I did not manage to watch this talk from Bob Hoffman, The Ad Contrarian yesterday. I wish I had; from the write up in Marketing Week […]
February 3, 2021Applying for, and being, a MyData OperatorI’m on a panel this afternoon at this Canadian Data Privacy Week event; the subject I’m due to discuss is as per the title above – […]
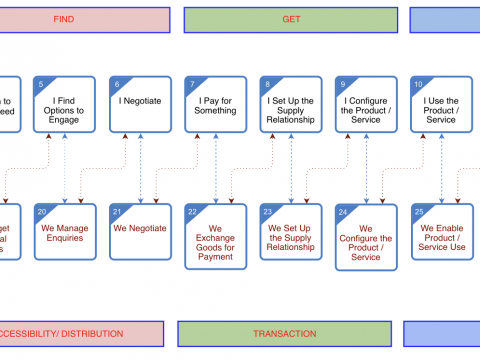
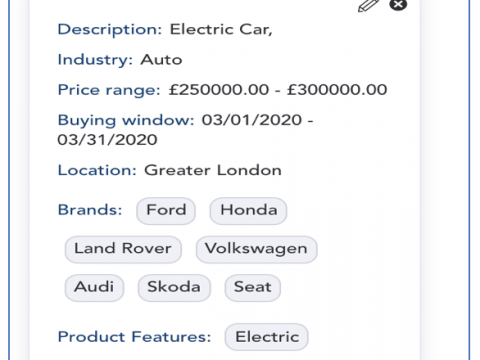
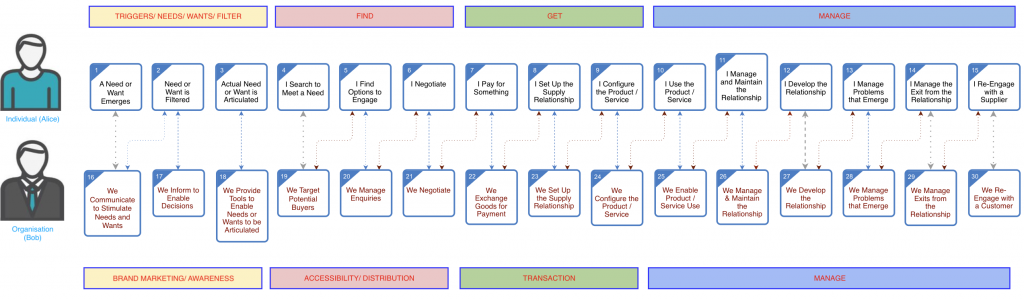
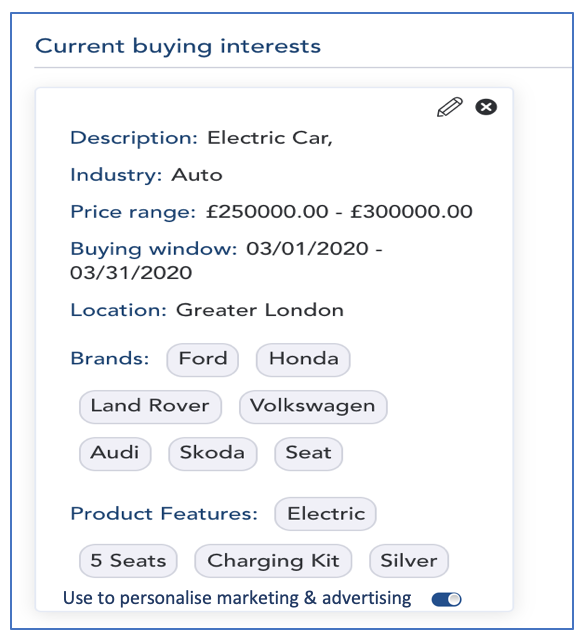
April 27, 2020Customer – Supplier Engagement Framework for the 20’sIn writing up this post, mainly for use in a presentation later today, i’ve just noticed that it’s been ten years since I last wrote about […]
February 6, 2020Personalisation – Who Should Drive?Yesterday I attended an excellent event hosted by Merkle in Edinburgh. There was a lot of very impressive content, tech and skills on show; the highlight […]
December 8, 2019How CustomerTech Can Improve Product/ Service ReviewsThis post writes up my take on a discussion on the VRM List, that initially asked the question ‘can reviews be made portable so that they […]
December 2, 2019It’s Time to Start Talking About Co-managed DataAs we reach the end of another decade, I’ve been reflecting on the changes over the last ten years in my areas of interest – customer […]
February 4, 2013The First Large Scale CRM Plus VRM Business?Nice to see Cheap Energy Club from MoneySavingExpert make it out the door, having worked on that for a big chunk of last year. At first glance […]
January 21, 2013A CRM plus VRM Venn for 2013I spent most of 2012 with head down consulting on a couple of big ‘CRM plus VRM’ propositions – more on those when they show up […]
February 27, 2010Filling in the Empty Space – The Personal Data StoreI said here that at present there are very few genuine VRM tools available right for use right now, and that the main reason for that […]


{kind=link}
{kind=link}
{kind=link}
{kind=link}