
Navigating challenges and opportunties around personal data
71+
Articles
50k
Words written
2004
Consulting Since
Recent Posts
December 6, 2022
I was asked to give a talk last week on how I thought the ‘data intermediaries’ space would evolve over the next few years. I used […]
March 26, 2021

I did not manage to watch this talk from Bob Hoffman, The Ad Contrarian yesterday. I wish I had; from the write up in Marketing Week […]
February 13, 2021
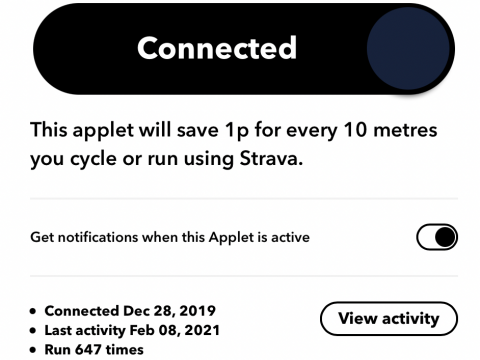
I mentioned the concept of Personal Algorithms, or (P)algorithms back in this post at the start of the Covid pandemic. I think they make for an […]
February 3, 2021

I’m on a panel this afternoon at this Canadian Data Privacy Week event; the subject I’m due to discuss is as per the title above – […]
January 28, 2021
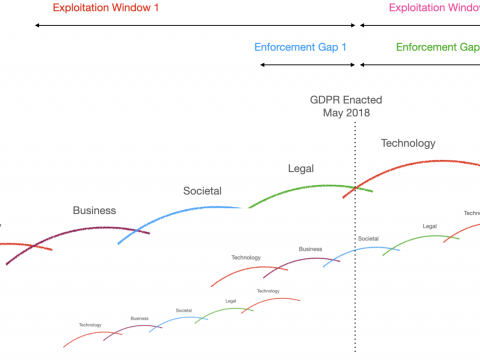
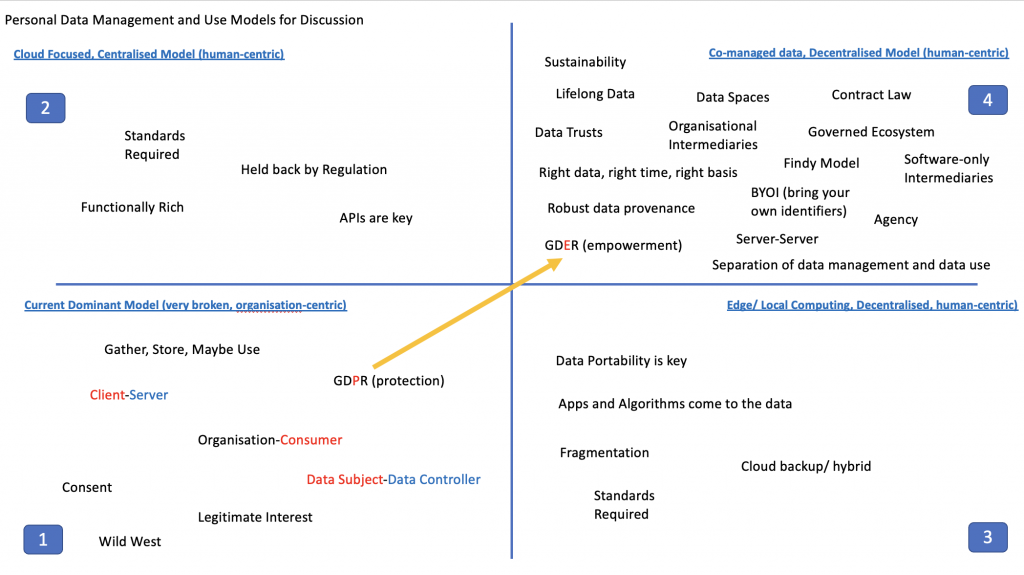{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
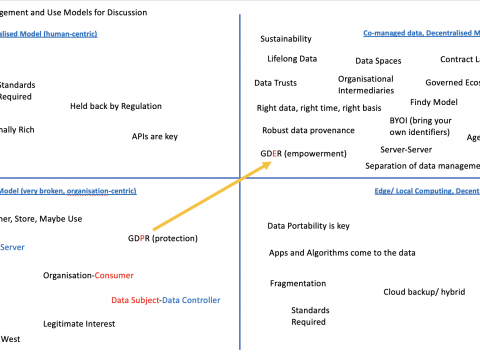
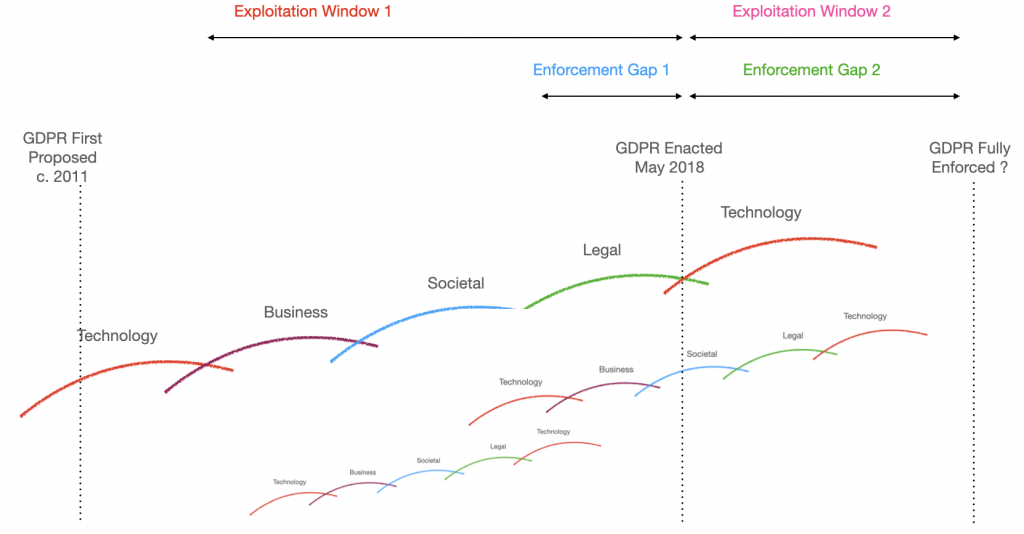
OK, yes the post heading is a bit obscure and for a specific audience; so let me explain. Over in the MyData.org community (and other such […]
January 15, 2021
Remember when it used to be an amusing conversation, ‘the amount of data in the world is growing at blah blah blah rate….’? I would contend […]