(P)algorithms
I mentioned the concept of Personal Algorithms, or (P)algorithms back in this post at the start of the Covid pandemic. I think they make for an important concept, so here are some more thoughts on them; plus some practical examples.
But first, a definition; I suggest:
‘A palgorithm is a specific sub-type of software supported algorithms that is fully transparent, actively controlled by one or more individuals, and run on their behalf by themselves or their acknowledged agents’.
In other words, a ‘palgo’ is ON YOUR SIDE by definition.
The key words in that definition are:
- ‘actively controlled by one or more individuals’ (i.e. palgorithms are switched on/ off by individuals, consciously)
- ‘fully transparent (i.e. palgorithms are easily readable and understandable; they do not require software or data science skills)
- ‘acknowledged agents’ (i.e. people can consciously delegate the build, deployment and management of palgorithms to other entities, including software agents)
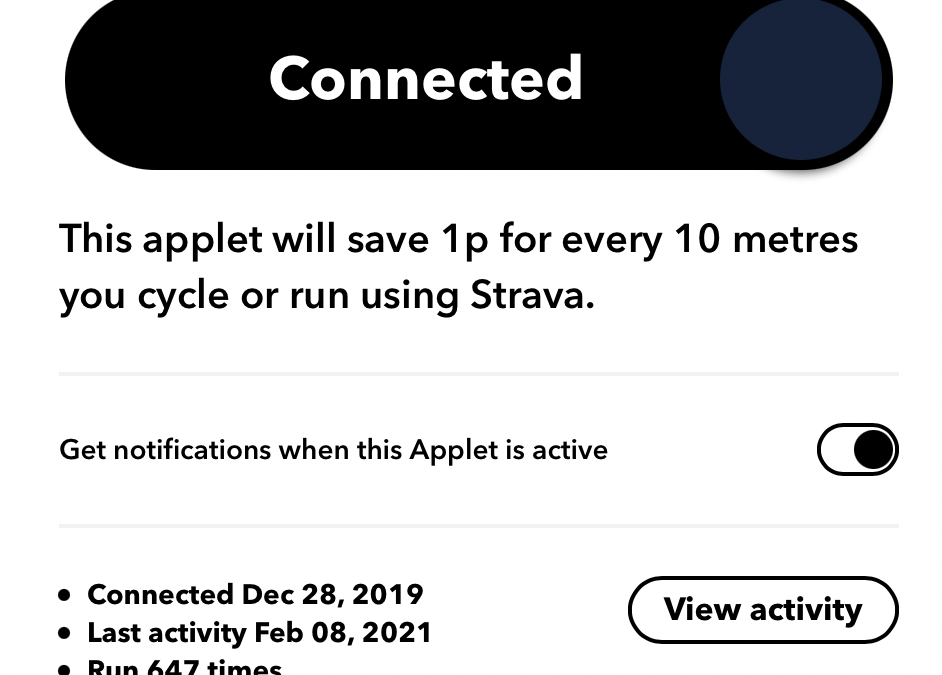
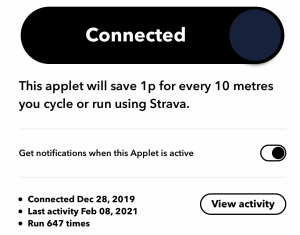
Below is an example of a palgorithm that I use and which has worked very well to help drive healthy habits through the Covid 19 pandemic. This one watches for when I log exercise, and puts 1p per metre of running or cycling into my ‘Hawaii Savings Account’ (yes, that’s the incentive I’ve set…).
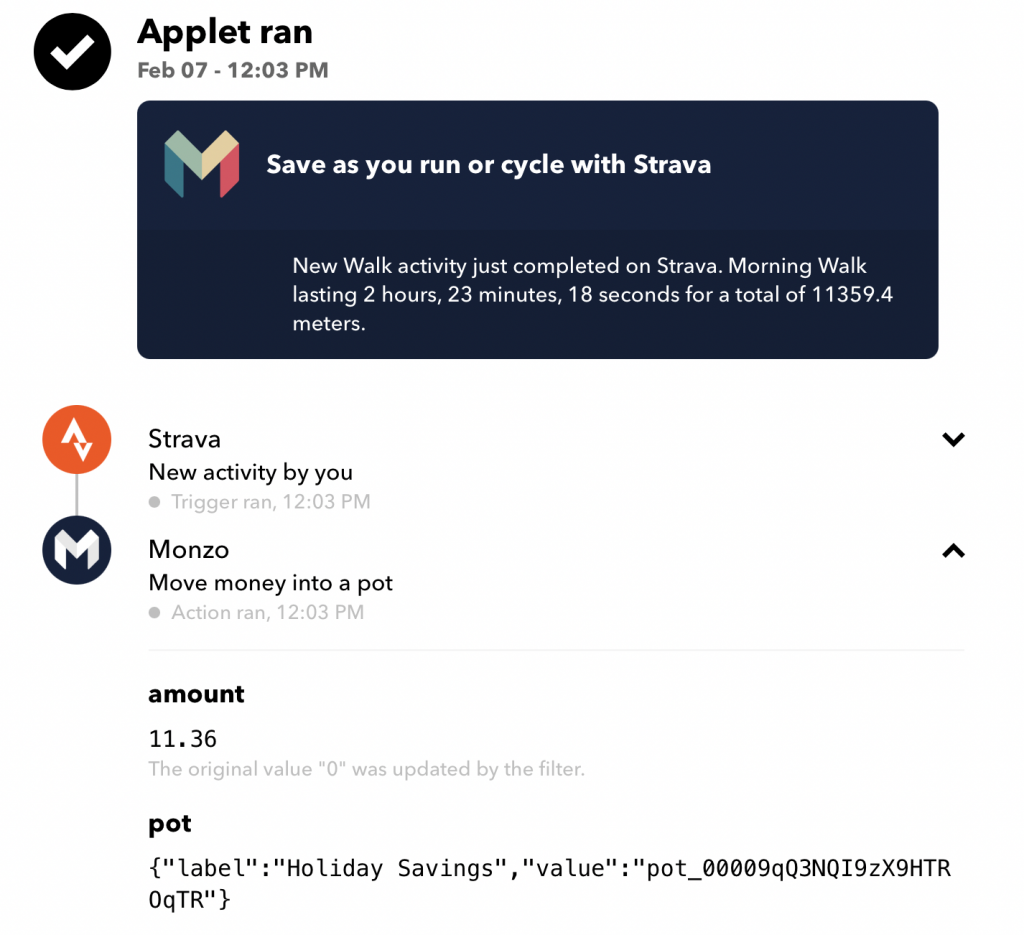
Here is a second, similar example. This one I use to make dealing with the large volume of rain we get in Scotland a bit easier; each time it rains where I live I transfer £5 into that Hawaii Savings Account.
Both of these examples require a ‘programmable’ bank account; i.e. a bank that has API’s that enable external services to connect and trigger actions (typically transactions). Open Banking has been an enabler for that, but in truth Monzo (and other challenger banks) are doing so as a customer experience improvement and enabler. But palgorithms can run on any data; all of the following can or should be programmable over time:
- My Calendar, the days, times and events within it
- My To Do List
- My Reminders
- My Subscriptions
- My Investments (funds, stocks and shares, pensions, savings accounts, insurances)
- My assets, products and services, (e.g. via picos for non-connected physical items)
- My Warranties
- The things I’m in the market for (Intentcasting)
- The adverts I see and marketing material I get exposed to
- My IoT sensors and trackers
- My Car
- My Location(s)
- My Music
- My Body (via wearables or embedded medical devices)
- My ‘agents’, i.e. the voice activation things like Alexa, Siri et al
I believe that the services offered by IFTTT, Zapier and similar that integrate API’s are excellent, but not the only way to deliver palgorithms. Many more ways will emerge over time as more open data API’s emerge, and personal data services solidify and build out their offerings. It seems to me that all that is required are identity management, data access, triggers, formulae, workflow and approval processes. Interestingly, unlike most VRM/ Me2B/ MyData scenarios, palgorithms don’t necessarily need personal data services as a precursor; they just need to be able access where it is at present. Of course, over time, as personal data services move more and more rich data to the side of the individual then palgorithms will become easier to run, and likely much more powerful as they will have richer, deeper fuel (data) to run on. Then machine learning and AI will push that further, not least by automating many of the resultant processes and interactions.
Certainly from my own experience above, running these palgorithms myself is much more useful and satisfying than having them run on me in less transparent and human-centric ways. And at current rates, my palgorithms should be paying for my family trip to Hawaii round about mid 2022; that has to be a good thing!!!