I was thinking about the many different components required to create a data eco-system that genuinely enables individuals and came up with the diagram below (now updated thanks to @varcan. I’m hoping to get feedback on this component list and the descriptions below. It is worth noting that the diagram should actually look an awful lot more complex than this; the current one only maps one individual to one supplier, whereas in the real world, an individual/ household can easily be managing 150-200 such relationships at any one time.
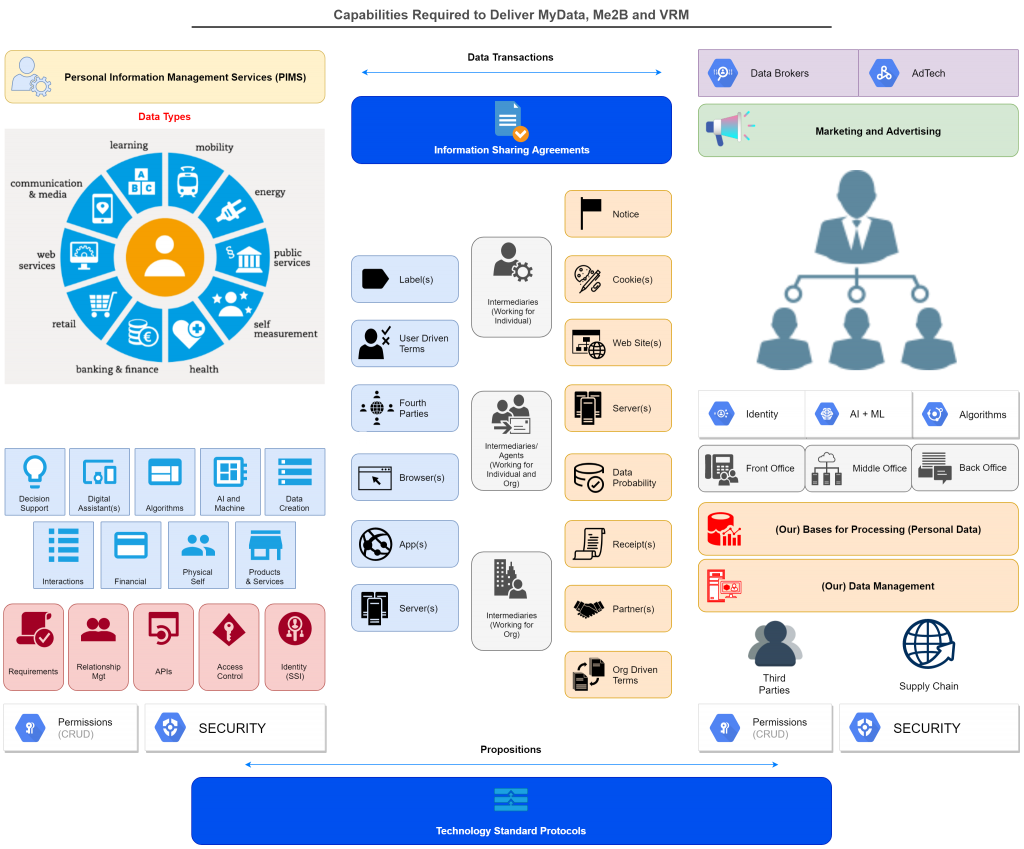
Individual side components
1. A Human (Alice) – at the core of this eco-system must be an individual will act as a point of origination and integration for data about themselves.
2. Personal Information Management Services (PIMS) – this umbrella term and what it implies should be the game changer and enabler. Until individuals begin to manage data in an empowering, connected way (or have that done on their behalf) then they will be at the behest of others who often do not have the necessary alignment of interests to do so. Ironically people already manage a great deal of information, but currently do so either offline, in un-connected silos like an Excel or Google sheet, or via proxies such as password managers or browser based store of account log-in details. The problem lies in that early PIMs services for individuals by definition have limited functionality; so there is a ‘chicken and egg’ situation – until people use such tools they won’t become more useful and see broader uptake.
3. Security – it is a given that data has value, and if not adequately secured it will be targeted and compromised.
4. Data Management – active management of data is required to ensure accuracy, timeliness, completeness, appropriateness, accessibility and multiple other facets in order to ensure the data in question is best fit for purpose
5. Permissions – when managed by the individual, permissions are typically the on-off switches that define what can be done with data over which the individual holds rights.
6. Data Types – data can represent and describe any number of things; not all have the same value, impact or threat. The management of data types and uses (requirements) for data is critical to ensuring data is used appropriately, and not in ways that are unhelpful, damaging or inappropriate. There are many different ways that one can categorise data related to people; and which to use depends on the purpose of the categorisation. Here is the one I use more than most for general insight into the subject area:
- General Types of Personal Data (from either individual or organisation perspective)
- Identifiers
- Demographic
- Descriptive
- Location
- Relationship(s)
- Intent
- Behavioural
- Preferences
- Permissions/ Consents
- Product/ Service Use
- Outlet/ Channel Use
- Interaction
- Financial Transaction
- Data Transaction (service management and meta data)
- More detail on the above data types is at this page
7. Identity (SSI) – In the digital world, control of identifiers defines how many processes are going to work, and who will be managing and using what data. Given the above, the concept and reality of ‘self-sovereign identity is a critical development that enables and protects individuals. It means an individual can ‘come to the party’ with at least some tools and capabilities of their own, and not thus at the total behest of the organisations they are interacting and transacting with.
8. Access Control – When an individual has their own data assets under management, enabling and controlling access to that becomes an important capability.
9. APIs – Moving data in and out, and managing the data within the data-sets managed by individuals will often be doing in automated ways by systems that are external to the individual. This will be done, in the main via APIs (application programming interfaces). Most main web service providers have API’s at present; few are fine tuned to the needs of individuals and PIMs at this stage but this will increase over time.
10. Relationship Management – An individual, or a group of individuals (e.g. a household) in the current modus operandi can easily be managing 150-200 silo-ed relationships with organisations; each with their own ways of doing things. Individuals require relationship management tools on there side to help them with managing the basic relationship plumbing.
11. My Data Creation – An individual will be the sole or co-creator for a huge amount of data over their lives; understanding and harnessing that data generation is a significant challenge, but also the key to unlocking many rich new capabilities. Many different types of data are generated and co-created by individuals; the three types set out below are particularly important:
- Location(s) – An individuals current location, historic locations, future locations and key locations are all valuable; so much of an individuals life is filtered by ‘where am I’
- Interactions – data on ‘who said what, to whom, about what, via what media is of great utility, positively if harnessed well, and negatively if released without suitable controls. Note, this data type includes ‘clickstream’, and as such
- Financial Transactions – data on money changing hands, inbound or outbound is obviously of value to many different parties. It is increasingly readily available via open banking protocols, albeit still under the control of regulated organisations.
12. Physical Self – the human body generates huge amounts of data over time and that is increasing quickly with developments such as biometric log in, quantified self and facial recognition.
13. My Products and Services – the ‘stuff’ that a person has is quickly becoming a huge source of data generation, analysis and use. Some products or services are inherently digital anyway, e.g. a bank account; others are part physical but now with a digital element, e.g. a mobile phone; a decreasing few remain solely physical; e.g. a bicycle (albeit most pure physical products will have a digital supply chain.
14. AI and Machine Learning – Computers can process any data in huge volumes, learn from that process, and apply the learned intelligence to any number of decision support processes
15. Algorithms – the data processing mechanisms that derive output data from inputs; they can be very positive or very problematic dependent on their author(s), their objectives and the quality of the design work. But well designed algorithms working FOR individuals and running on rich, personally controlled data-sets will be a powerful force for good.
16. Digital Assistants – Looking beyond todays voice activated surveillance machines, it must be possible to envisage digital helpers with open source code, API’s to enable inter-connectedness, and person-centric business models
17. Requirements – This somewhat amorphous term is actually a critical synthesis of context, interaction and transaction; it is the digital embodiment of demand driving supply
18. Decision Support – Life is complex, and full of decisions; data plus the right decision support tools can save people significant time and money, and enable better all round decisions
19. Helpful Cookies – Those that do helpful things like store user names to avoid repetitive data entry, or provide feedback to trustworthy supplier on site use are normally a good thing for the site user. The downside is that their use is often used to cover up that other less helpful cookies (i.e. tracking and surveillance) are also in place.
20. User Driven Terms – Customer Commons has led work on the concept that the user of a site or service can proffer one or more terms of use of their choice. Most typically these relate in some way to data sharing; individual typically would ideally like to minimise data shared whereas organise tend to wish to maximise that.
21. Information Sharing Label(s) – There have been a number of projects that have sought to deliver standardised ways to label or certify (as per food labelling) a data sharing scenario in order to better inform individuals who might engage with it.
22. Server(s) (individual) – Much of what is wrong with the corporate surveillance based model is from the ‘client-server’ modus operandi, with ‘server’ as the dominant party and ‘client’ not having a whole lot of choice in the engagement. As such, it has been suggested that if individuals had their own ‘server’ then there would be a great chance of a peer to peer model evolving, or even one where the individual dominated for specific use cases. To date this has not translated into reality at scale, no proposition has as yet been able to make that a technical reality that could scale.
23. App(s) – Whilst technically an app lives on devices run by individuals, they are often returning significant quantities and types of data back to the supply side.
24. Browser(s) – In their original guise, browsers provided individuals with an independent web surfing tool that they could drive any which way they wished with no baggage. That changed with the advent of the cookie and became turbo-charged in a negative direction by Adtech. Ad-blocking browser plug-ins have had huge success by preventing adverts reaching their end target, albeit do not as yet prevent the data leakage that drives real time bidding and Adtech in the first place. Browser manufacturers, typically, try to find the fine line between protecting and enabling users, and building sustainable businesses with sufficient revenues to thrive.
25. Data Transactions – Every data transaction should generate a record, just as every monetary transaction does; they do not at present and that favours those who would prefer the data transactions they drive to remain hidden. Data transactions could be recorded in a modernised equivalent of a bank or credit card statement and made available for either or both parties to further use in any way they wish.
26. Information Sharing Agreements – These are more evolved variants of todays silo by silo privacy policies. An information sharing agreement, when seen from the individual and the organisational perspective in B2C or C2B, is more transparent, more accessible, and often re-usable by others with similar needs.
27. Audit Logs – These record every change made in a data-set or connected data relationship. The can be temporary, or kept on a permanent basis and made accessible to both/ all relevant parties via distributed ledger technology.
28. Intermediaries (or agents) Working for Individuals – examples include major real world service providers such as doctors, lawyers, consumer support services (e.g. Which), independent financial advisers/ wealth managers, retail banks, and concierge services; or digital tools such as password managers.
29. Intermediaries (or agents) working for both Individuals and Organisations – examples include Google, Facebook, Comparison shopping providers, private sector consumer advice services (e.g. Money Saving Expert, Trip Advisor, Trusted Reviews)
30. Intermediaries (or agents) working for Organisations – these include external services used in ‘customer onboarding/ know your customer processes (e.g. identity checks, credit bureau); publishers who host advertisements could also be seen in this category.
31. Propositions – These are rounded, packaged user experiences that built on top of technologies (software and hardware), data exchanges, markets and business models. Typically, a well worked out and balanced customer proposition is required to reach mass market scale in a B2C (or C2B) environment.
32. Technology Standards and Protocols – Beneath any proposition or component ‘stack’ lie some lower level technologies and ways of doing things. Ideally we wish to see all technologies and protocols in the ‘MyData’ stack to be open source so that what they are doing, and how they are doing it is very clear, visible to anyone who cares to look, and able to be improved over time.
33. Data Portability – This is a key concept and capability in the MyData eco-system; it requires that an individual should be able to ‘port’ their data from one service provider to another. GDPR mandates that this ported data must be in machine readable form. Architectural choices exist around precisely how this porting must happen; ideally the individual should be the point of integration, i.e. ported data should route through the individual, and not simply be passed from one organisation to another. Subject access, i.e. ‘let me see/ give me a copy of the data you hold on me’ is a closely related capability, subject acecss has long been a facet of more advanced privacy laws.
34. Server(s) (organisations) – these are acting as the master in the client – server world, dictating the choices (or lack) of choice available to ‘clients’.
35. Web Site(s) – These primary digital spaces owned and controlled by organisations are key components in an organisations data gathering capability; they often have related ‘apps’ which put front ends to the web site on the devices run by individuals.
36. Tracking Cookies – These devices, and their close cousin trackers buried in mobile phone applications, are the primary weapons of the Adtech industry. Masked by organisation-centric privacy policies and terms and conditions noted below, these lines of code within browsers have the simple job to gather data about individuals and move that to the world of surveillance capitalism.
37. Privacy Notice – Organisations, at least those covered by stronger privacy laws such as in EU, are required to provide privacy notices that, theoretically at least, allow an individual about to interact (i.e. share data with) the organisations
38. Organisation Driven Terms – Alongside a privacy notice, organisations will typically have terms and conditions for using their site/ service which will include a reference to the privacy policy, as well as other terms of use. This can include data related terms that may not be referred to in the privacy policy itself; for example ‘data transfer policy on a corporate acquisition). There is no hard and fast rule around what specifically needs be in each of privacy notice and terms of service; this lack of standardisation is a major problem in that, by definition, no one supplier will be the same as another from the individual perspective.
39. Partner(s) – In this context, organisations will often seek to share data with ‘their partner network’. Historically this could have been assumed to be relatively constrained to genuine partners; but nowadays that could simply be a metaphor for selling data into the Adtech. Data Broker and other eco-systems.
40. Data Receipts – Building from the long established of practices of organisations providing receipts for monetary transactions, this line of activity makes it possible to get a receipt for providing data. The Kantara consent receipt specification is a solid start point for this line of work.
Within Organisation (Bob)
41. Identity – Organisations have been managing (digital) identities for many years; since the earliest days of remote commerce having a ‘customer number’ has been the norm. As technology has evolved, the number and type of these identities has multiplied, and many organisations will now have many different identities related to a single customer record.
42. Machine Learning and Artificial Intelligence – This long touted suite of technical capabilities allows more computers to process more things, more quickly. That becomes very important when data volumes continue to increase at exponential rates. However, given that data growth is, in many ways, out of control, or at least out of the control of the individual (data subject), then machine learning and artificial intelligence carry considerable risks, not least around the automated build and use of ‘consumer profiles’ around individuals.
43. Our Bases for Processing Personal Data – Whilst not every individual or organisation worldwide is governed by the GDPR, that regulation has very helpfully articulated the six (and only six) reasons why an organisation might legally process personal information. These can be extrapolated across all organisations whether they are governed by GDPR or not, doing so gives us all a better understanding of who is doing what with our data, on what grounds. The 6 reasons why an organisation could be processing your personal data are:
- Consent,
- Contract,
- Legitimate Interest,
- Legal Obligation,
- Vital Interest,
- Public Tasks
It is critical to understand that these bases for processing are designed to be applied at a granular level. A single data attribute (e.g. email addresses) might require multiple separate bases for processing depending on the purpose for which the data is being used. This example from Arsenal Football Club nicely illustrates the above scenario.
44. Permissions (CRUD) – Actual technical changes to personal data are governed separately to the legal bases for processing. Technical changes are governed by ‘who/ what has the right to Create records, Read records, Update records and Delete records.
45. Our Data Management – this is organisations managing data on their customer; i.e. the individuals on the left side of the diagram. It is not about organisations managing their own many other types data for their own purposes. This includes, for example, the HR systems which will store significant personal data on past, present and some future employees, product data, pricing data, supply chain data.
46. Security – information security is a given when holding customer personal data; privacy law and common business sense demands a high grade as many organisations are commonly under attack from fraudsters. And yet, data breaches remain common, and increasingly costly in terms of fines and bad publicity.
47. Algorithm(s) – Many organisations now have algorithms in their customer facing activities, even though some may not know that they do so. Algorithms, and the often related profiling of customers is increasingly problematic in terms of privacy; GDPR allows customers to object to automated profiling and insist of decisions about them being made by humans.
48. Front Office (Relationship Management tools) – These include CRM (e.g. Salesforce), Marketing Automation, Customer Experience, e-Commerce, and various other tools that are principally about managing and optimising customer interaction (when seen from the organisational perspective).
49. Marketing and Advertising – A significant proportion of organisational expenditure is very often spent in the marketing and sales budgets. These are tasked with building and progressing a sales pipeline (funnel), brand building, customer experience, customer engagement and building trust (although the latter can be very challenging with so highly data driven as marketing tends to be nowadays.
50. Data Brokers – These organisation build up and re-sell huge troves of personal data, mainly into marketing services or as credit reference agencies. They have a significant challenge in that they process data on individuals without normally having a direct relationship with that individual.
51. Adtech – This general term hides many practices that have evolved over the last decade, and which are now seen as primary participants in/ enablers of ‘surveillance capitalism’. Much of what Adtech does happens in the split second between an individual clicking on something in their browser or phone app, with aderts being auctioned and then delivered based on profiles built up within the Adtech eco-system. Publishers (those with audiences), Data Management Platforms, Advertisers, Advertising Exchanges, Demand Side Platforms, Supply Side Platforms and Consent Management Platforms are the main sub-sets of the Adtech market, with the individual stuck in the middle.
52. Other Third Parties – These further components of the personal data eco-system around a supplier might include delivery services, financial services or any other entity involved somehow in service delivery that gains personal data for that reason.
53. Supply Chain – Most organisations will have supply chains over and above their data management eco-system; each supply chain component may also be managing personal data in their own right.