Co-managed data, subject access and data portability
I’ve written a fair bit of late on the importance of co-managed data; here and here again. This follow on drills into how co-managed data between individuals and their suppliers would change how we typically think about both subject access and data portability.
Subject access has featured in pretty much all privacy legislation for 20 years or so. It has always been assumed to be ‘if an individual wishes to see the data an organisation holds on them then they have the right to do so’. Typically that has meant the individual having to write to the relevant data protection officer with a subject access request, and then that resulting in a bundle of paper print out showing up a few weeks later. My last one is shown below; it was incomplete and largely useless, but at least validated my view that subject access had not moved on much since GDPR.

Data portability has been around for less time, as a concept sought by a bunch of interested individuals, and only appeared in legislation with GDPR in 2018. The theory is that individuals now have the right to ask to ‘move, copy or transfer personal data easily from one supplier environment to another in a safe and secure way, without affecting its usability’. However, when I tried that, the response was wholly underwhelming. I’ll no doubt try again this year, but I fully expect the response to be equally poor.
The problems in both of the above, in my view, is that organisations are being given the remit to make the technical choices around what is being delivered as subject access and data portability responses. In that scenario they will always default to the lowest common technical denominator; anything else would be like asking turkeys to vote for X’mas. So, think .csv files delivered slowly, in clunky ways designed to minimise future use rather than the enabling formats and accessibility the data subjects would like to see.
Moreover, the issue is not just the file format. There is also a mind-set challenge in that the current norm assumes that individuals are relatively passive and non-expert in data management, and thus need to be hand held and/ or supported through such processes so as to avoid risk. Whilst yes there may be many in that category, there are also now many individuals who are completely comfortable with data management – not least the many millions who do so in their day jobs.
So, in my view there is little to be gained by pursuing data subject access and data portability as they are currently perceived. Those mental and technical models date back 20 years and won’t survive the next decade. As hinted at above, my view is that both subject access and data portability needs could be met as facets of the wider move towards co-managed data.
So, what does that mean in practice? Let’s look at the oft-used ‘home energy supply’ example (which adds competition law into the mix alongside subject access and data portability). Job 1 is relatively easy, to publish the data fields to be made accessible in a modern, machine-readable format. An example of this is shown at this link, taking the field listing from the original UK Midata project and publishing it in JSON-LD format (i.e. a data standard that enables data to be interoperable across multiple web sites). What that very quickly does is cut to the chase on ‘here’s the data we are talking about’ in a format that all parties can easily understand, share and ingest.
My second recommendation would be to not put the supply side in charge of defining the data schema behind the portable data; i.e. the list of fields. Doing so, as before, will lead to minimum data sharing; whereas starting and finishing the specification process on the individual side will maximise what is shared. There is more than enough sector specific knowledge now on the individual side (e.g. in the MyData community) for individuals to take the lead with a starter list of data fields. The role of the organisation side might then be to add specific key fields that are important to their role, and to identify any major risks in the proposals from individuals.
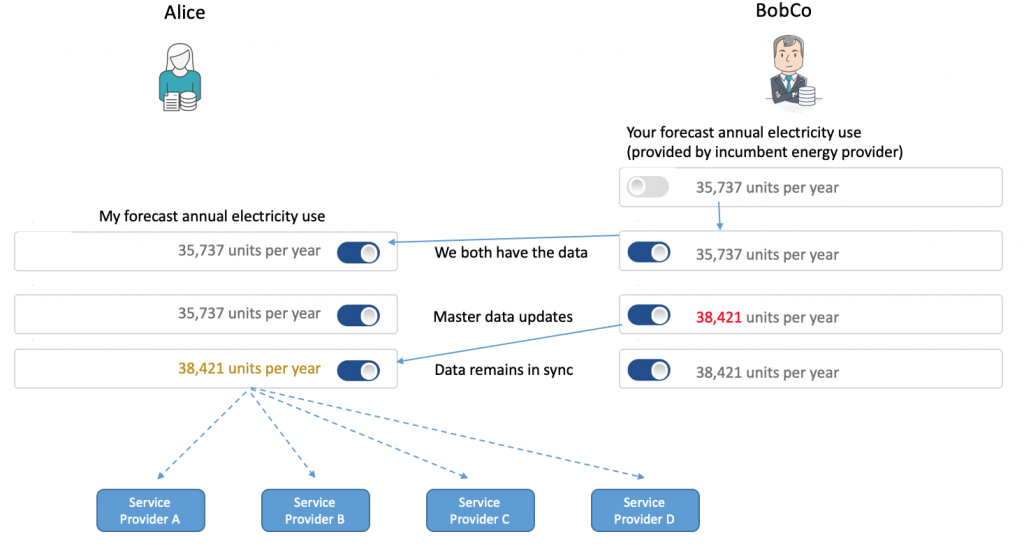
Third, as hinted at in the post title; both subject access and data portability will work an awful lot better when seen in a co-managed data architecture. That is to say, when both parties have tools and processes that enable them to co-manage data; then ‘export then import’ goes away as a concept, and is replaced by master data management and access control. In the diagram below, BobCo (the home energy provider) is necessarily always the master of the data field (algorithm) ‘forecast annualised electricity use’ as this is derived from their operational systems (based on Alice’s electricity use rate). But Alice always has access to the most recent version of this; and has that in a form that she can easily share with other parties whilst retaining control. That’s a VERY different model to that enacted today (e.g. in open banking) but one that has wins for ALL stakeholders, including regulators and market competition authorities.
Fourth recommendation, which is almost a pre-requisite given how different the above is to the current model, is to engage in rapid and visible prototyping of the above – across many different sectors and types of data. Luckily, sandboxes are all the rage these days, and we have a JLINC sandbox that allows rapid prototyping on all of the above – very quickly and cost effectively. So if anyone wishes to quickly prototype and evaluate the above model just get in touch. Obvious places to start might be standard data schema for ‘my job’, ‘my car’, ‘my tax’, ‘my investments’, ‘my transaction history’ on a retail web site, ‘my subscription’, ‘my membership’ ‘my child’s education history’ and no doubt some more easy ones before one would tackle scarier but equally do-able data-sets such as ‘my health record’. To give you a feel for what I mean by rapid prototyping; all of the above could be up and running as a working, scalable prototype within a month; versus within a decade for the current model….