The Personal Data Eco-System
This post is a short(ish) summary of a working session led by Drummond Reed and me at the recent West Coast VRM Workshop, and also an introduction to the Kantara workgroup in which we are going to move this debate forward. It is also part of the thinking that will short emerge in a Mydex white paper.
At the VRM workshop, we discussed the need for the concept of the Personal Data Store, what it would do in practice, and what that will ultimately enable.
Why we need such things – because individuals have a complex need to manage personal information over a lifetime, and the tools they have at their disposal today to do so are inadequate. Existing tools include the brain (which is good but does not have enough RAM, onboard storage, or an ethernet socket……thankfully), stand alone data stores (paper, spreadsheets, phones, which are good but not connected in secure ways that enable user-driven data aggregation and sharing), and supplier based data stores (which can be tactically good but are run under the supplier provided terms and conditions). NB Our current perception of ‘personal data stores’ is shaped by the good ones that are out their (e.g. my online bank, my online health vault); what we need is all of that functionality, and more – but working FOR ME.
What they will do/ enable – the term Personal Data Store is not an ideal term to describe a complex set of functions, but it is what it is until we get a better one (the analogy I’d use in more ways than one is the term ‘data warehouse’ – again a simplistic term that masks a lot of complex activity). A Personal Data Store can take two basic forms:
Operational Data Stores – that get things done, and only need store sufficient breadth and depth of data to fulfill the operation they are built for (e.g. pay a credit card bill, book a doctor’s appointment, order my groceries).
Analytical Data Stores – that underpin and enable decision making, and which typically need a more tightly defined, but much deeper data-set that includes data from a range of aspects of life rather than just that from one specific operation (e.g. plan a home move, buy a car, organise an overseas trip).
A sub-set of the individual’s overall data requirement will lie in both of the above, this being the data that then integrates decision-making and doing.
In both cases, the functionality required is to source, gather, manage, enhance and selectively disclose data (to presentation layers, interfaces or applications).
We also discussed ‘who has what data on you’ and introduced the following diagrams to explain current state and target state (post deployment of Volunteered Personal Information (VPI) tech and standards).
The key terms that require explanation are:
My Data – is the data that is undeniably within, and only within, the domain of an individual. It’s defining characteristic is that it has demonstrably not been made available to any other party under a signed, binding agreement. This space has been increasingly encroached upon by technology and organisations in recent history (e.g. behavioural tracking tools like Phorm) and this encroachment will continue. Indeed a general comment can be made that ‘my data’ equates to privacy in the context of personal data; so the rise of the surveillance society and state is a direct assault on ‘My Data’. Management of ‘My Data’ can be run by the individual themselves, or outsourced to a ‘fourth party service’.
Your Data – is the data that is undeniably within the domain of an organisation; either private, public or third sector. Proxy views of this data may exist elsewhere but are only that. This data would include, for example, the organisations own master records of their product/ service range, their pricing, their costs, their sales outlets and channels. Customer-facing views of much of Your Data is made available for reproduction in the ‘Our Data’ intersect.
Our Data – is the data that is jointly accessible to both buyer and seller/ service provider, and also potentially to any other parties to an interaction, transaction or relationship. It is the data that is generated through engaging in interactions and transactions in and around a customer/ supplier relationship. Despite being ‘our’ data, it is probably technically owned, or at least provided under terms of service designed by the seller/ service provider; in practical terms this also means that the seller/ service provider dictates the formats in which this data exists/ is made available.
Their Data – is the data built/ owned/ sold by third party data aggregators, e.g. credit bureaux, marketing data providers in all their forms. It’s defining characteristic is that it is only available/ accessible by buying/ licensing it from the owner.
Everybody’s Data – is the public domain data, typically developed/ run by large, public sector(ish) entities including local government (electoral roll), Post Offices (postal address files), mapping bureau (GIS). Typically this data is accessible under contract, but the barriers to accessing these contracts are set low – although often not low enough that an individual can engage with them easily.
The Basic Identifier Set/ Bit in the Middle – this is the core personal identity data which, like it or not, exists largely in the public domain – most typically (but not exclusively) as a result of electoral rolls being made available publicly, and specifically to service providers who wish to build things from them. This characteristic is that which enables the whole personal eco-system and its impact on data privacy to exist, with the individual as the un-knowing ‘point of integration’ for data about them.
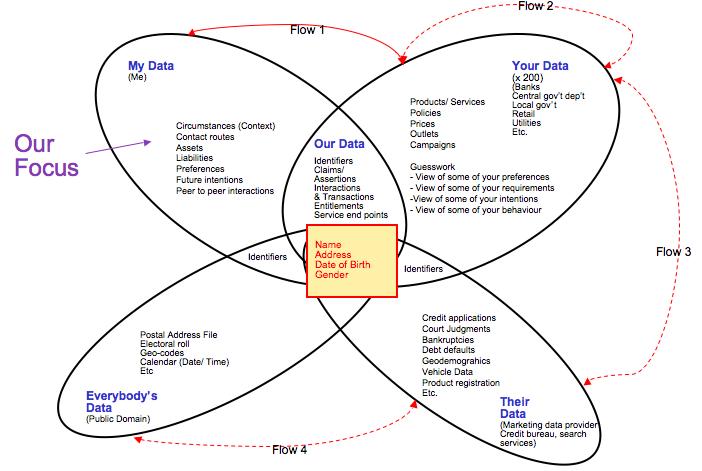
The ovals in the venn diagram represent the static state, i.e. where does data live at a point in time. The flow arrows show where data flows to and from in this eco-system; I use red to signify data flowing under terms and conditions NOT controlled by the individual data subject.
Flow 1 (My Data to Your Data, and My Data to Our Data) – Individuals provide data to organisations under terms and conditions set by the organisation, the individual being offered a ‘take it or leave it’ set of options. Some granularity is often offered around choices for onward data sharing and use, i.e. the ‘tick boxes’ we all know and which are one of the main bitsof legacy CRM that VRM will fix.
Flow 2 (Your Data to Your Data, including Our Data) – Organisations share data with other organisations, usually through a back-channel, i.e. the details of the sharing relationship are typically not known to the data subject.
Flow 3 (Your Data, including Our Data to Their Data) – Organisations share data with a specific type of other organisation, data aggregators, under terms and conditions that enable onward sale. Typically the sharer is paid for this data/ has a stake in the re-sale value.
Flow 4 (Everybody’s Data to Their Data) – Data Aggregators use public domain data sources to initiate and extend their commercial data assets.
The target state is shown below, a different scenario altogether – and one which I believe will unfold incrementally over the next ten years or so…..data attribute by data attribute, customer/ supplier management process by customer/ supplier management process, industry sector by industry sector. In this scenario, the individual and ‘My Data’ becomes the dominant source of many valuable data types (e.g. buying intentions, verified changes of circumstance), and in doing so eliminates vast amounts of guesswork and waste from existing customer/ citizen managment processes.
The key new capabilities required to enable this to happen are those being worked on in the User Driven and Volunteered Personal Information work groups at Kantara (one tech group, one policy/ commerce one), and elsewhere within and around Project VRM. The new capabilities will consist of:
– personal data store(s), both operational and analytical
– data and technical standards around the sharing of volunteered personal information
– volunteered personal information sharing agreements (i.e. contracts driven by the individual perspective, creative commons-like icons for VPI sharing scenarios)
– audit and compliance mechanics
Around those capabilities, we will need to build a compelling story that clearly articulates, in a shared lexicon (thanks to Craig Burton for reminding us of the importance of this – watch this space), the benefits of the approach – for both individuals and organisations.
The target state that will emerge once these capabilities begin to impact will include the 4 additional individual-driven information flows over and above the current ones. The defining characteristic of these new flows is that the can only be initiated by the data subject themselves, and most will only occur when the receiving entity has ‘signed’ the terms and conditions asserted by the individual/ data subject. The new flows are:
Flow 5 (My Data to Your Data (inc Our Data) – Individuals will share more high value, volunteered information with their existing and potential suppliers, eliminating guesswork and waste from many customer management processes. In turn, organisations will share their own expertise/ data with individuals, adding value to the relationship.
Flow 6 (Everybody’s Data to My Data) – With their new, more sophisticated personal information management tools, individuals will be able to take direct feeds from public domain sources for use on their own mashups and applications (e.g. crime maps covering where I live/ travel)
Flow 7 (My Data to (someone else’s) My Data) – An enhanced version of ‘peer to peer’ information sharing.
Flow 8 (My Data to Their Data) – The (currently) unlikely concept of the individual making their volunteered information available to/ through the data aggregators. Indeed we are already starting to see the plumbing for this new flow being put in place with the launch of the Acxiom Identity Card.
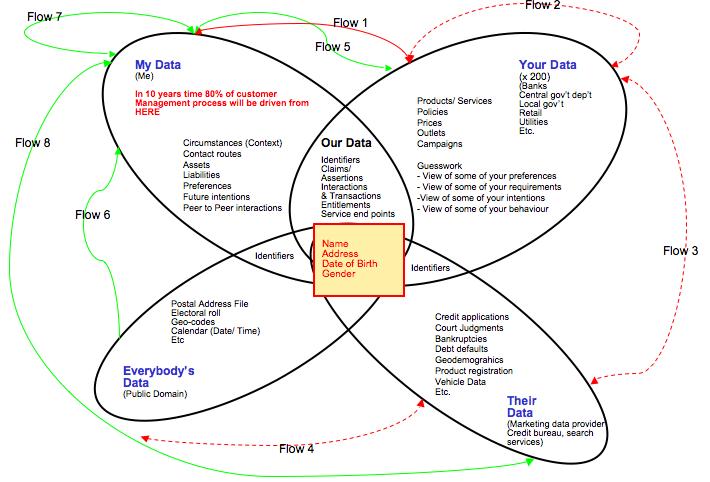
The implications of the above are enormous, my projection being that over time some 80% of customer management processes will be driven from ‘My Data’. I’m pretty confident about that, a) because we are already see-ing the beginning of the change in the current rush for ‘user generated content’ (VPI without the contract), and b) because the economics will stack up. Organisation need data to run their operations – they don’t really mind where it comes from. So, if a new source emerges that is richer, deeper, more accurate, less toxic – and all at lower cost than existing sources; then organisations will use this source.
It won’t happen overnight obviously; as mentioned above specific tools, processes and commercial approaches need to emerge before this information begins to flow – and even then the shift will be slow but steady, probably beginning with Buying Intention data as it is the most obvious entry point with enough impact to trigger the change. That said, the Mydex social enterprise already has a working proof of concept up and running showing much of the above working. A technical write up of the proof of concept build can be found here. And the market implications of this are explored in more detail in new research on the market value of VPI shortly to be published by Alan Mitchell at Ctrl-Shift.
The two hour session at the VRM workshop was barely enough to scratch the surface of the above issues, so the plan is to continue the dialogue and begin specifying the capabilities required in detail in the User Driven and Volunteered Personal Information (technology) workgroup at The Kantara Initiative. The workgroup charter can be found here. A parallel workgroup focused on business and policy aspects will also be launched in the next few weeks. Anyone wishing to get involved in the workgroup can sign up to the mailing list here and we’ll get started with the work in the next couple of weeks.
1 Comment
This is a real conceptual breakthrough.
I really enjoyed hearing about this at the VRM Palo Alto session, even more for how it was received and the quality of added thinking that came forward.
It’s a wonderful thing to be able to look foward into the future and see such important changes, and to be able to share this thinking in an open spirit of enquiry and excitement.
Let’s work to hang on to that spirit. The lovers of money will be all over this soon and the noie will be deafening. Let’s make sure that anyone who matters knows who the real pioneers were.