
Navigating challenges and opportunties around personal data
71+
Articles
50k
Words written
2004
Consulting Since
Recent Posts
May 11, 2020

AKA – MyData and Coronavirus, Take 2… I first wrote on the subject of Mydata and Coronavirus back on 8th March; just over two months, but […]
April 27, 2020
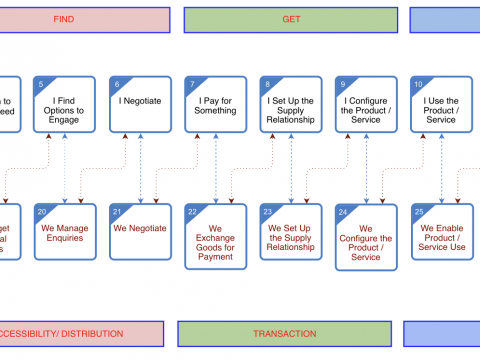
In writing up this post, mainly for use in a presentation later today, i’ve just noticed that it’s been ten years since I last wrote about […]
April 5, 2020
Well, it’s not every day one starts a blog post with such a title; but these are not ordinary times. So let’s dive in… Key Point […]
March 8, 2020
Check out the quote below overheard by Doc Searls, my co-conspirator at Customer Commons. That’s spot on…. And it points towards things that need to be […]
February 17, 2020
There seems to be a growing recognition in the privacy/ data empowerment spaces that data portability and data interoperability across service providers are important things. I […]
February 6, 2020
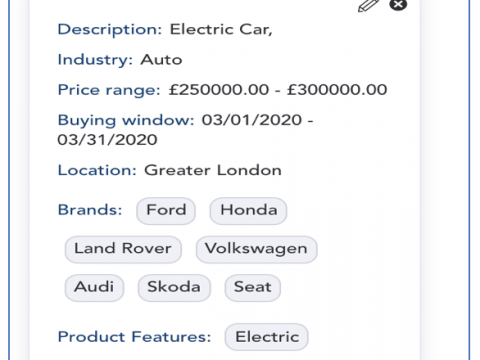
{kind=link}
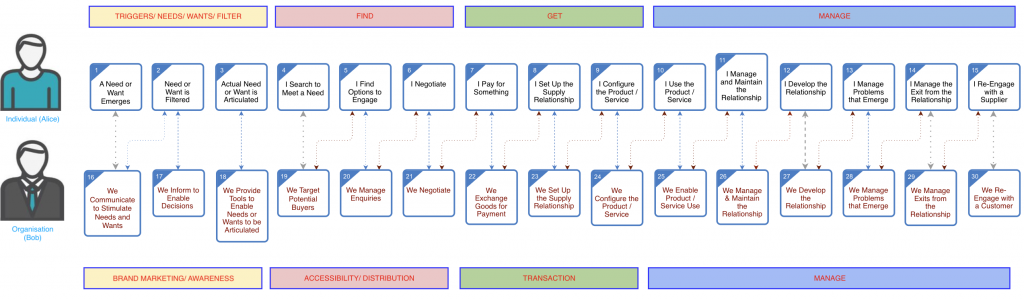{kind=link}
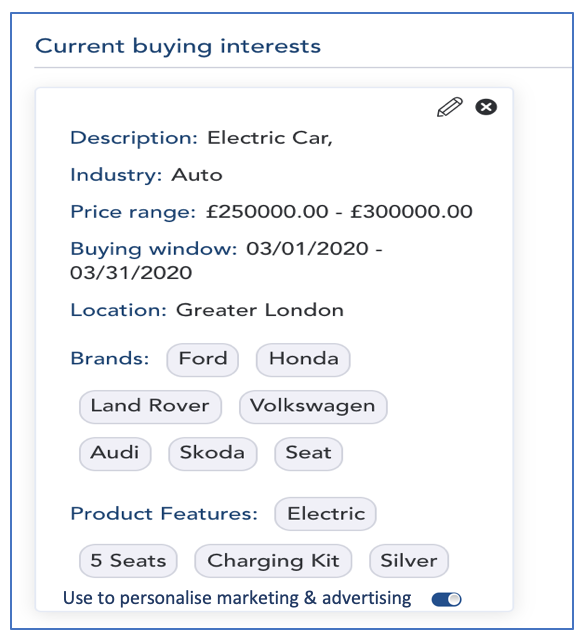{kind=link}
Yesterday I attended an excellent event hosted by Merkle in Edinburgh. There was a lot of very impressive content, tech and skills on show; the highlight […]