March 26, 2021Is Marketing about to wake up from its Adtech nightmare?I did not manage to watch this talk from Bob Hoffman, The Ad Contrarian yesterday. I wish I had; from the write up in Marketing Week […]
February 13, 2021(P)algorithmsI mentioned the concept of Personal Algorithms, or (P)algorithms back in this post at the start of the Covid pandemic. I think they make for an […]
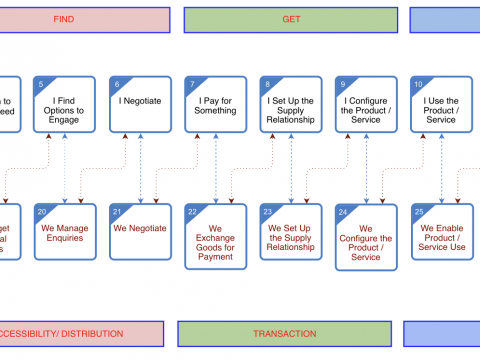
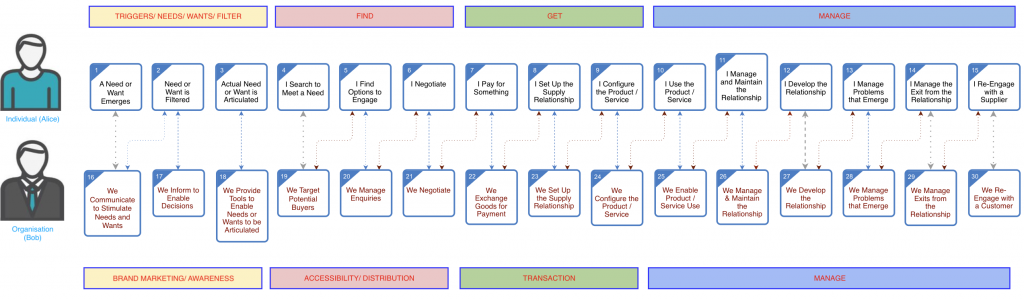
April 27, 2020Customer – Supplier Engagement Framework for the 20’sIn writing up this post, mainly for use in a presentation later today, i’ve just noticed that it’s been ten years since I last wrote about […]
December 8, 2019How CustomerTech Can Improve Product/ Service ReviewsThis post writes up my take on a discussion on the VRM List, that initially asked the question ‘can reviews be made portable so that they […]
January 21, 2013A CRM plus VRM Venn for 2013I spent most of 2012 with head down consulting on a couple of big ‘CRM plus VRM’ propositions – more on those when they show up […]
February 27, 2010Filling in the Empty Space – The Personal Data StoreI said here that at present there are very few genuine VRM tools available right for use right now, and that the main reason for that […]
January 25, 2010The Customer – Supplier Engagement FrameworkOver the past few months, The Information Sharing Work Group at The Kantara Initiative has done a bit of a deep dive into an end to […]
July 22, 2009More on the Privacy Fight-backNow this is nice….self-destructing digital data controlled by the data subject…..
July 17, 2009Who Said Privacy Was Dead…..?BT decides against deploying Phorm behavioural tracking. The mobile phone directory Connectivity/ 118800 shut down by pressure from individuals who did not want their details scraped […]

{kind=link}
{kind=link}
{kind=link}